When you apply for cloud funds from CloudBank, those funds are being taken from a communal pool of dollars allocated to CloudBank by your NSF directorate. We ask that you submit a proposal so we can determine that you will be using these funds cost-effectively and pro-socially, ensuring the maximum number of your colleagues can take advantage of this shared resource pool.
We have reviewed more than 300 requests at this point and most requests are ultimately approved, but depending on the quality of the submission this may take multiple drafts and much back-and-forth communication with our support team. The purpose of this guide is to help you put together a great proposal that can be approved immediately and get you on the cloud within weeks rather than months.
Anatomy of a proposal
The goal of your proposal is to explain the computational infrastructure needed for your research, and provide a budget breaking down your total dollar request into the concrete resources that you will be using.
This proposal consists of two parts:
- A cost estimate from the official cost calculator of your chosen cloud platform, which takes the form of a budget for cloud resources over the next 12 months. Ultimately, the calculator will give you a “share” link for your budget which you will copy and paste into the proposal.
- A written justification that briefly introduces us to your research and then, in detail, explains why you need the items listed in your cost estimate. This justification should be two to four paragraphs long, or 200 to 500 words.
Justification guidelines
Level of scientific detail
The focus of your written justification should be on why you need the quantity and performance level of the cloud resources that you are requesting. As a part of this, you should very briefly describe the research you are doing and how it will be furthered by these resources. That said, we don’t want a detailed description of your science, what makes it novel, or a justification of its merit. The NSF has already vetted and approved the scientific integrity of your work. We are solely interested in vetting and approving your plan for cloud infrastructure.
✅👍 Looks good
Our research focuses on the transistor-level synthesis of next-generation branch predictors for SIMD processors. The EDA tools necessary to do this synthesis are highly parallelizable and heavily CPU-bound, and so our estimate requests a large number of CPU-optimized VMs. We budgeted 10 c5.4xlarge virtual machines to perform a round of chip synthesis, which we will do approximately six times in the coming year. We also budget a 100 GB object storage bucket to keep our results.
⛔👎 Is less helpful
Our research focuses on advancing the state of the art for branch predictors in SIMD processors by building on the results of Foobar et. al with the novel introduction of a wide crossbar to swizzle the bloom filters associated with each data input during the instruction decode stage (ID). The ID stage has traditionally been the bottleneck of previous architectures, and in our work we hope to demonstrate the directly proportional relationship between crossbar width and instruction throughput on the SPEC89 and SPEC92 benchmarks. This work will need a large quantity of computational resources to complete in a reasonable amount of time.
Justify using compute capacity, not personnel
The number of VMs needed really depends on how computationally demanding the work is, rather than now many folks will be doing it. If you have multiple members of your lab, you don’t necessarily need each to have their own VM. Demonstrate the resources one user would need, and from there how many VMs will be necessary to handle your workforce size.
✅👍 Looks good
Our simulations take 30 minutes to run on a 4-core machine. We’ll have 8 graduate students working on this project and want them each to be able to run simulations as needed, so we’re requesting two c5.4xlarge VMs, each of which has 16 cores.
⛔👎 Is less helpful
We have 10 graduate students in our lab, so we humbly request 10 c5.4xlarge VMs.
Benchmark your workloads
Where possible, benchmark the workloads you’ll be running ahead of time and use those benchmarks to make more accurate VM estimates. How long does your workload take to run on a machine with specifications similar to those you’ll be using in the cloud? Note the machine’s CPU cores, GB of RAM, GPU count and GPU model. Use this figure to estimate how long you’ll need to leave your VMs on for. Include this usage figure in the cost estimate from the official calculator.
✅👍 Looks good
Doing one round of chip synthesis takes 14 hours on a lab workstation with 16 cores and 32 GB of RAM. Since we expect to do around 10 synthesis runs a month, we estimate that we’ll use a c5.4xlarge VM (16 vCPU / 32 GB RAM) and leave it on for around 140 hours/month.
⛔👎 Is less helpful
Chip synthesis is very computationally intensive and takes a long time, so we expect to need our VM on for ~150 hours / month.
Which of your specifications are flexible?
Most computational research could benefit from an unbounded amount of computational resources, but our financial resources are finite. Where applicable, indicate which of your specifications are hard requirements and which could be reduced to save money while still making scientific progress.
✅👍 Looks good
We are requesting 50 c5.9xlarge VMs to search the parameter space of our simulation. We could make do with fewer VMs, although this will decrease the amount of space we can search before our paper deadline. We cannot use a smaller VM, though, because of hard limits on the RAM requirements of our simulation software.
⛔👎 Is less helpful
Our simulation is very resource-intensive, and so we need 50 c5.9xlarge VMs to search the large parameter space.
Combining a CloudBank award with a pre-existing cloud account
It's unfortunately not possible to deposit CloudBank funds into a pre-existing cloud account. Instead, as a part of the onboarding process, a new account is created for you within CloudBank’s organization and you are given the login details to it. In rare circumstances we have also migrated pre-existing accounts into our organization, but at that point all of its resources must be paid for with your CloudBank funds and you will no longer have root user level access to the account.
If you have pre-existing cloud infrastructure that you need to use, please explain your integration plan in your written justification and include detailed information about your computational usage thus far to give us more context about why you need the resources you do; we need as much detail as we would for a new research project that hadn’t yet started. Leaving this information out of your application may result in delayed processing, as we will have to get in touch with you to confirm that this account separation is ok.
✅👍 Looks good
Our award originally budgeted funds to run 30 chip simulations, but because of unexpected paper acceptances (yay!) we have needed to run more. To extend the scope of our work, we will need 2 c5.9xlarge VMs to run 72 hours/week. This will allow us to run enough simulations to meet the next paper deadline. Since this account will be running in parallel with our old one, we also budget 30 GB of object storage to hold a copy of our core dataset.
⛔👎 Is less helpful
Because of unexpected paper acceptances (yay!) we have needed to run more simulations than we originally budgeted for, and so these CloudBank funds will help extend the scope of our work.
Period of eligibility
CloudBank awards are only valid for the duration of your NSF award. For NSF awards with less than one year remaining, please only request funds for the number of months remaining in your award. If the cost estimate you include specifies funds for a full year, make sure to pro-rate this amount in the actual total you request. You can request a supplement later on if you get a cost or no-cost extension approved by the NSF. Regardless, please mention the limited duration of your award in the justification text.
✅👍 Looks good
Our NSF award expires three months from the time of this request submission, so although the included cost estimate is for $24000 we prorate this amount to arrive at a total request of $6000.
⛔👎 Is less helpful
[award expires in 3 months but is not mentioned in justification]
Sensitive data and privacy regulations
CloudBank accounts must not be used to store protected or sensitive data that requires compliance protection within any legal regulatory framework. This includes data covered by laws like HIPAA and FERPA. If your research involves human-related data, please specify that you will only be working on public datasets or de-identified data in your justification. If in doubt about whether this is relevant, lean towards describing the lack of regulatory protection in your justification anyway. Otherwise, CloudBank's review board may follow up about this over email which will delay your award.
✅👍 Looks good
Our research involves training machine learning models on the usage data of bus riders within our university's local transit system. This dataset is de-identified and not protected under any regulatory framework.
⛔👎 Is less helpful
Our research involves training machine learning models on the usage data of bus riders within our university's local transit system.
Cost estimate guidelines
Uptime estimation
The biggest difference between cloud machines and traditional computers is that cloud machines are priced per hour of “on” time. When you add a VM to your cost estimate, the default settings will assume the machine is being left turned on 24/7, and this can cause a shockingly high estimate.
To keep costs manageable, it’s vital to understand when you’ll actually be using a machine, and take steps to ensure it’s turned off when you’re not using it.
Here are a few of the most common usage patterns we see in research scenarios:
- Interactive workstation - If researchers will be interactively using a VM (like, for example, through an ssh session or a Jupyter notebook), it’s safe to estimate that the VM will only be on for 40 hr/week. In the cost calculator, find the VM’s usage estimation settings and specify a weekly rate of 40.
- “Set-and-forget” workloads / job submission - Much research involves computational methods that run for tens of hours (or days). This includes things like training a machine learning model or running numerical simulations of physical systems. In cases like this, estimate how many hours one “job” takes, and how many jobs you will run on average per month. In the cost calculator, find the VM’s usage estimation settings and specify this as your monthly usage rate.
- High-availability - Sometimes, a VM really does have to be on all the time. This is often when computers provide an externally available API or webserver. In these cases, either try to use the cheapest VM you can get away with or figure out if you can actually adapt to the above “set-and-forget” pattern.
In all of the above situations, you’ll want to select “constant” usage models and “on-demand” pricing schemes in the calculator. The “constant” does not refer to being constantly on, but rather a periodically consistent usage pattern. The “on-demand” refers to the fact you’re only paying for the VM when it’s turned on.
✅👍 Looks good
Our researchers will be experimenting with synthesis tools on 3 c4.4xlarge VMs, which we estimate to be on at 40 hr/wk for a subtotal of $415/mo. Additionally, we provision 2 p3.8xlarge VMs for long-running synthesis jobs. These jobs take about 20 hours to run and we expect to run 6 per month, so each VM is estimated at a usage of 60 hr/month for a subtotal of $1468/mo. All together, we are requesting $23000 for 12 months of work.
⛔👎 Is less helpful
We will use 3 c4.4xlarge VMs to experiment with synthesis tools, and these will cost $1743/mo. We will also need 2 p3.8xlarge VMs for long-running synthesis jobs, which will cost $17800/mo. All together, we are requesting $240000 for 12 months of work.
Note the orders of magnitude above — uptime estimation reduced the 12-month project cost from $240,000 to $23,000.
Workload graphs on AWS
The AWS cost calculator offers several different “workload” representations for estimating VM costs. The selection looks something like this:

We suggest always choosing constant usage, even if your VMs are not going to be on constantly. You’ll still have the opportunity to specify the amount of time they are to be left turned on, if you scroll down further and select the “On-Demand” box:
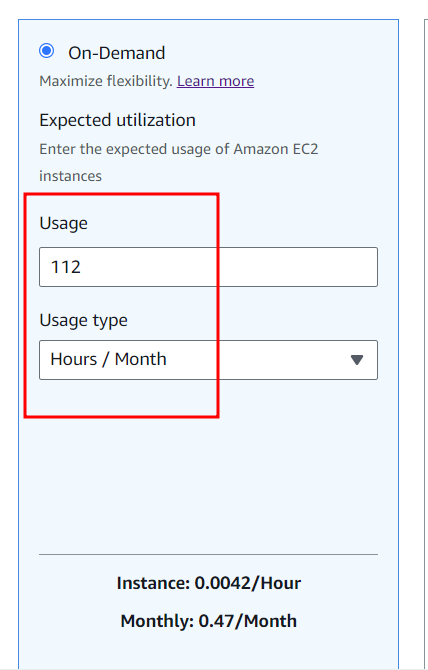
The main use for the other workloads are for clusters of always-available servers that will always have a minimum number running 24/7. If you do use this workload estimation type, keep in mind that a non-zero baseline number (circled above in red) implies that at least some VMs will be on 24/7, and unless you actually intend for this to be the case it can greatly increase your cost estimate.
If you submit a cost estimate with a workload estimated in this way, we will probably reach out to you to confirm that this is what you intended. In general, we suggest just sticking with the “constant usage” workflow.
Multi-cloud use
CloudBank allows your award to fund cloud accounts on multiple platforms. If you plan on utilizing multiple cloud platforms, please explain how your funds will be distributed across them and include a cost estimate for each. The request submission form supports the addition of multiple cost estimate links for this purpose, by clicking the “ADD ANOTHER ITEM” button underneath the link box.
Discount plans
Most major cloud platforms offer some form of virtual machine pricing discount when you commit to using them for some sustained amount of time, usually 1 or 3 years. On Azure and AWS these are called reserved instances and savings plans. On GCP this is called a committed use discount. This is all in contrast to the standard cloud “pay-as-you-go” pricing, also called on-demand pricing.
The rule of thumb is that discount plans are financially worth it only if you plan to leave your VM turned on for more than ⅔ of the year. Otherwise, they result in you (and CloudBank) paying for 100% uptime of the machine whether you are using it or not. We find for almost all scientific workloads, on-demand pricing is more economical.
If you do opt to use a discount plan, it’s important to explain your rationale for it in your written justification. Please also note that CloudBank cannot accommodate savings plans that will extend beyond the duration of your NSF award. If your estimate includes a discount plan that is not well-justified or extends beyond your award period, the review board will deny your request and ask you to re-estimate using on-demand pricing.
Spot instances
Spot instances, also known as pre-emptible instances and transient servers, are virtual machines offered for a substantial (~60-80%) price discount in exchange for the possibility that your machine may be unpredictably shut down by the cloud provider (”evicted”). Other than the potential for eviction, these VMs behave and perform exactly like their regularly priced counterparts.
Although eviction may sound like a deal breaker, in recent years many scientific computing tools and libraries have been introduced to make using spot instances second nature. Here are a few we recommend:
- SkyPilot (https://skypilot.readthedocs.io/en/latest/) SkyPilot is a general-purpose tool out of UC Berkeley’s Sky Computing Lab for packaging your computational code and running it on cloud resources, including spot VMs. CloudBank and SkyPilot are tightly integrated, and support resources are available for adopting it into your workflow.
- Dask (https://www.dask.org/) Dask is a Python library designed for offloading computations on exceptionally large datasets across multiple machines, including cloud VMs and spot instances. Any Python code that uses numpy arrays or pandas dataframes can be easily ported to use Dask.
- NextFlow (https://www.nextflow.io/) NextFlow is a tool to compose “computation pipelines” for scientific workflows. It supports most tools and programming languages that show up in traditional UNIX environments, and can offload stages of computation to preemptible cloud VMs.
- TensorFlow/Keras/PyTorch Almost all commonly used machine learning libraries have some sort of support for checkpointing on pre-emptible compute instances. AWS and Azure in particular provide platform-specific machine learning environments that make using spot instances easier. On AWS, this platform is called SageMaker. On Azure, this platform is called Azure Machine Learning.
To include any of the above in your resource request, just modify the VMs in your cost estimate to use spot instances and then mention your approach in the written justification. CloudBank's support team is always available to help you make use of these tools, and doing so can reduce the cost of your work significantly.
Bare-metal machines and dedicated tenancy
As an alternative to traditional VMs, cloud platforms offer various plans to allow the user more access to the underlying physical hardware:
- “Dedicated tenancy” or “sole tenancy” guarantees you are the only customer placing VMs on a given server, and often give you access to the underlying system and VM scheduler.
- “Bare metal instances” are similar to dedicated tenancy, but rather than giving you the opportunity to create VMs on a given machine, you are just given access to the underlying machine itself.
In cost calculators, these options will show up as VM types with “metal” or “dedicated” in their name. In GCP’s calculator, the former also appears as a “Sole tenancy” section at the bottom of a compute resources estimate.
In practice, we find that these options are almost never necessary, and when they are they are rarely price-competitive against other NSF-sponsored HPC programs such as SDSC Expanse. Cost estimates that include bare-metal instances are in most cases denied, and otherwise need a very strong justification for their necessity.
Storage
The virtual disks attached to VMs, also called block storage, tend to be among the more expensive ways to store data in the cloud, and we don’t suggest using them to store large datasets (> 100 GB). Generally, this space is useful for storing code you’ve written, software you use, and as a temporary staging place for the sub-sections of your dataset you are actively using. If you’re trying to represent cloud data storage in your cost estimate, don’t do so by selecting large disks when configuring VMs.
The most cost effective way to store these datasets is with object storage, which roughly corresponds to a disk that lets you access individual files through an HTTP API. The next most effective way to store data is in file stores, which are roughly equivalent to networked file servers. These all have different names on the various cloud platforms, which are expressed in the following matrix:
| Block storage ($$$) | File storage ($$) | Object storage ($) | |
|---|---|---|---|
| AWS | EBS | EFS | S3 bucket |
| Azure | Disk storage | File store (part of a “storage account”) | Blob container (part of a “storage acocunt”) |
| GCP | Persistent Disks | Filestore | Cloud storage |
| IBM | Cloud block storage | Cloud file storage | Cloud object storage |
We recommend you use object storage for your cost estimate even if you do not initially have experience using it, as we strongly encourage our users to migrate to it over time and they can save quite a lot in their budget by doing so.
When budgeting for this data storage, cost calculators will ask you what level of read/write performance you need, using names like performance tiers or provisioned IOPS. We don’t recommend using anything above “standard tier” file storage quality as it can steeply increase the cost of your cloud infrastructure. Requests including high-performance data storage will need to provide rigorous benchmarks demonstrating its necessity, or else be rejected by the review team.
Making data available archivally
We ask that you use object storage to store the results of your work long-term and make them publicly available (that is, if you are required to or are planning to do so). This holds even if your project doesn’t have a need for particularly large amounts of storage as described in previous sections.
The reason for this is that, even when your VMS are turned off, your results stored on their inactive virtual disks still costs an order of magnitude more than it would in object storage and with the formerly-used VM deleted.
We ask that if in your justification you mention making results available to the general public, you include the details about its storage in your cost estimate.
Regional price differences
On larger cloud platforms, the price of your infrastructure can vary quite a bit depending on which geographic region you select. The most pronounced case of this is with AWS’s local zones, which are designed to reduce latency to a minimum for services like financial trading and video streaming. In practice we have never seen a research application for which its latency requirements justified the extra pricing of an AWS local zone, and if you estimated using one we will ask you to resubmit your estimate in a larger and cheaper region.
Right-sizing VMs
Because of on-demand VM pricing, it’s possible to budget for multiple types of machines that are each sized to handle a specific portion of your workload. Say, you might use a VM with two GPUs to test out ML training parameters for a week and then switch to two VMs with eight GPUs each to perform a 72-hour round of training on your full dataset. This process is called “right sizing”. Consider identifying if you can apply right-sizing to your workload, and if so include multiple VMs in your cost estimate to reflect this. Applications that express right-sized infrastructure help us better understand your needs and go a long way towards justifying larger budgets.